
GloVe
Identify topics, create predictive models, measure word similarity, and generate word embeddings for NLP tasks.
- Freemium
- Web, API
- CodeProductivity
- Free plan available
- No credit card
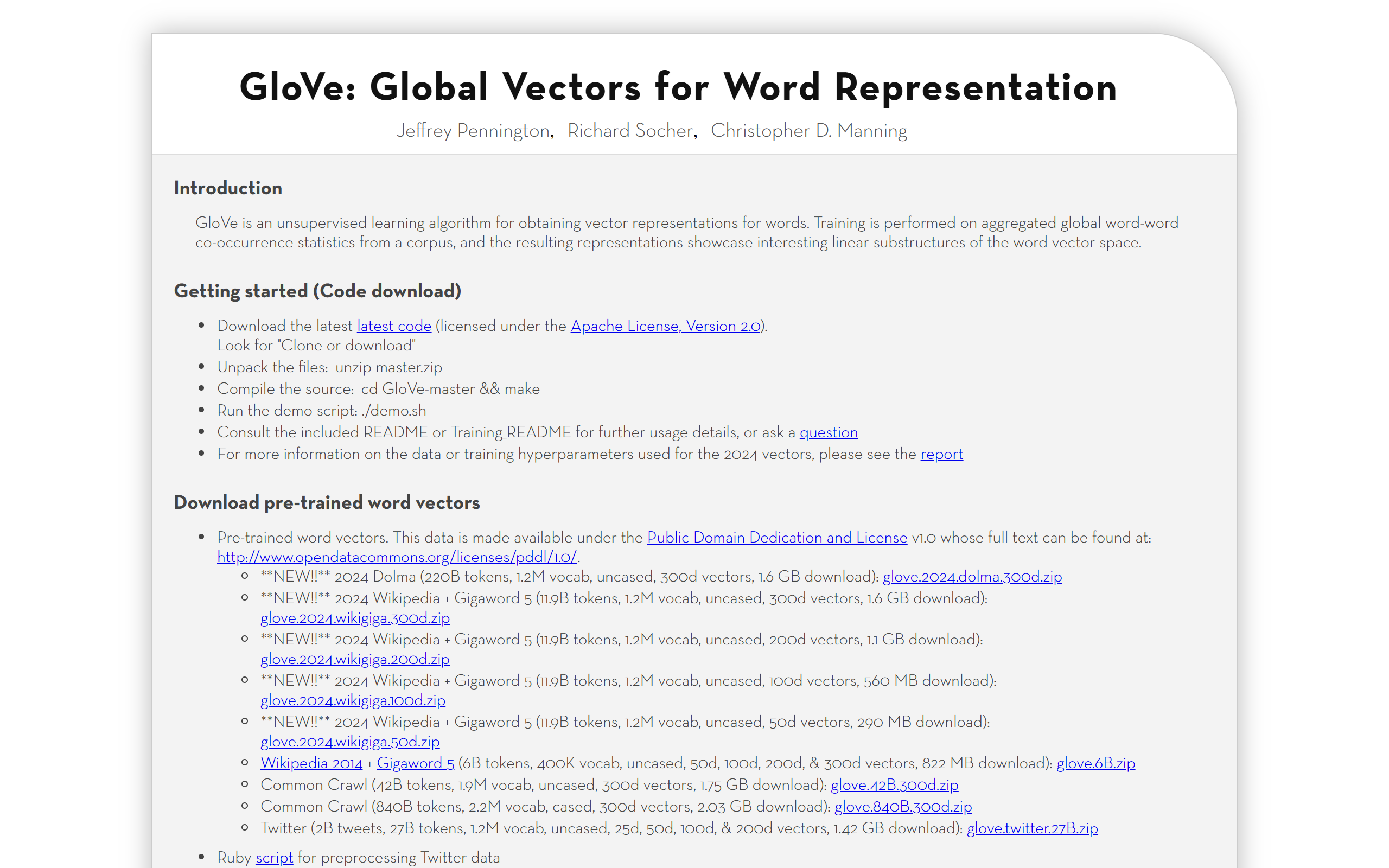
What is GloVe?
Key features
Word embedding generation
creates numerical vector representations of words based on co-occurrence statistics
Word similarity measurement
calculates how semantically related two words are using the trained embeddings
Pre-trained models
provides ready-to-use embeddings trained on common corpora like Wikipedia and Common Crawl
Customisable training
allows you to train embeddings on your own text data for domain-specific vocabularies
Topic identification
embeddings can be used to identify and cluster related topics within documents
Predictive model support
embeddings serve as input features for building downstream machine learning models
Pros & cons
Advantages
- Free and open-source with no licensing restrictions
- Faster training time compared to some alternative embedding methods
- Pre-trained models available for immediate use without training from scratch
- Well-documented with strong community support from Stanford and the research community
- Works well for capturing both syntactic and semantic word relationships
Limitations
- Requires some technical knowledge to install, train, and integrate into projects
- Performance can vary depending on corpus quality and size; smaller datasets may produce less reliable embeddings
- Newer transformer-based models like BERT often outperform GloVe on many modern NLP benchmarks
Use cases
Building recommendation systems that measure document or text similarity
Creating word similarity and analogy solvers for quiz or educational applications
Training custom embeddings for domain-specific text analysis in fields like medicine or finance
Feature extraction for text classification, sentiment analysis, and other supervised learning tasks
Analysing vocabulary relationships in corpus linguistics and language research
Ready to try GloVe?
Pricing
Free
Free
Full access to open-source code, pre-trained embedding models, and ability to train custom models
Get started with GloVe
Click through to GloVe and start using it now.
- Free plan available
- No credit card