LightTag
Annotate text, validate data, and find relevant information with an AI-powered search tool.
- Freemium
- Web, API
- Data & AnalyticsWritingResearch
- Free plan available
- No credit card
What is LightTag?
Key features
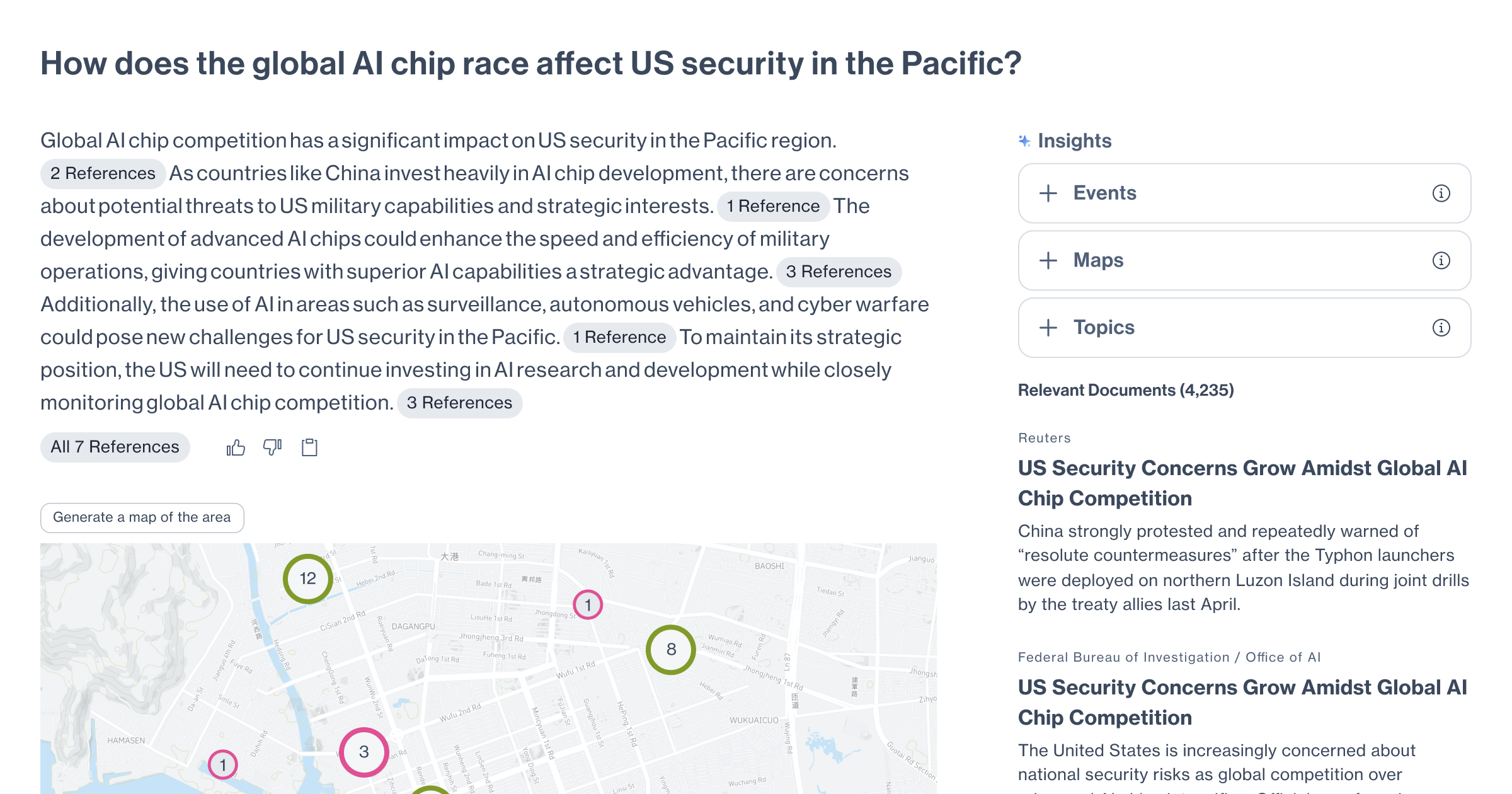
Text annotation interface
label text documents with customisable categories and tags
Collaborative annotation
multiple team members can work on projects simultaneously with access controls
AI-assisted labeling
machine learning suggestions to help speed up annotation
Data validation
tools to check annotation consistency and identify quality issues
Search and filtering
find specific annotated data points across your dataset
Project management
organise annotation tasks and track completion progress
API access
integrate with external tools and automate workflows
Pros & cons
Advantages
- Significantly faster to prepare training data with AI-assisted suggestions
- Collaborative features allow distributed teams to work on the same project
- Validation tools help maintain high-quality, consistent annotations
- Straightforward to set up and start annotating without technical expertise
- Search functionality makes it easy to find and navigate large datasets
- Free tier allows individuals and small teams to get started without cost
Limitations
- Costs can scale quickly for very large annotation projects or many team members
- Setting up complex annotation schemes requires careful planning
- Free tier includes limitations on project size and number of collaborators
- May need custom development to integrate with some existing data pipelines
Use cases
Labeling training data for natural language processing and machine learning models
Preparing data for named entity recognition and text classification tasks
Creating datasets for sentiment analysis and topic categorisation
Validating data quality across large corpora of text documents
Organising and categorising unstructured text for knowledge management
Generating training data for fine-tuning language models
Ready to try LightTag?
Pricing
Free
Free
Basic text annotation, limited projects and team members, core labeling and validation tools
Pro
Contact sales
Unlimited projects, advanced AI features, expanded collaborator limits, API access
Enterprise
Contact sales
Custom deployment options, dedicated support, SSO and advanced security, custom integrations
Get started with LightTag
Click through to LightTag and start using it now.
- Free plan available
- No credit card