
LLMtary
Local LLM Red-Teaming Tool
- Freemium
- Web
- AI LLMOps & FrameworksDeveloper Tools
- Free plan available
- No credit card
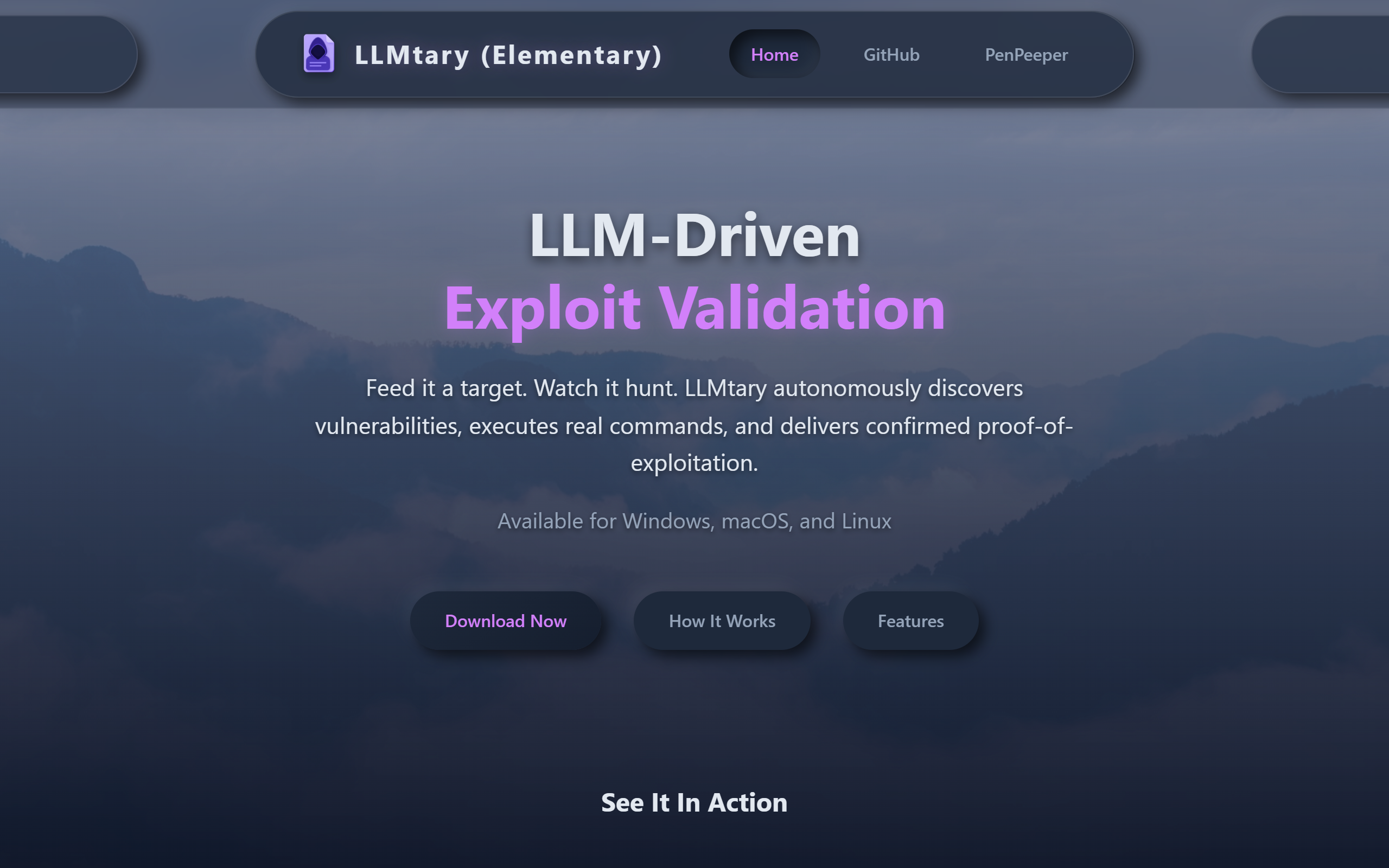
What is LLMtary?
Key features
Local model testing
Run red-teaming exercises against LLMs hosted on your own hardware
Adversarial prompt generation
Create and execute test prompts designed to expose model weaknesses
Response analysis
Evaluate model outputs for harmful content, inconsistencies, or undesired behaviour
Result logging
Document test cases and outcomes for audit trails and improvement tracking
Privacy-focused
All testing remains on your infrastructure; no data leaves your environment
Pros & cons
Advantages
- Complete data privacy; no external API calls or cloud data transmission during testing
- Cost-effective for ongoing security testing without per-request fees
- Helps identify safety gaps before deploying models to production or end users
- Suitable for iterative development workflows where frequent testing is needed
Limitations
- Requires sufficient local compute resources to run LLMs, which can be expensive or time-consuming
- Limited to testing models you can host locally; not suitable for evaluating commercial closed-source models
- Effectiveness depends on the quality and breadth of test prompts you create or configure
Use cases
Safety validation before deploying a fine-tuned LLM to a production environment
Academic research into model robustness and adversarial resilience
Internal security audits of proprietary language models
Iterative model improvement by identifying and addressing failure modes
Compliance documentation for regulated industries requiring model evaluation records
Ready to try LLMtary?
Pricing
Premium
Contact for pricing
Advanced analysis tools, priority support, and additional testing frameworks
Get started with LLMtary
Click through to LLMtary and start using it now.
- Free plan available
- No credit card