
N0x
LLM inference, agents, RAG, Python exec in browser, no back end
- Free plan available
- No credit card
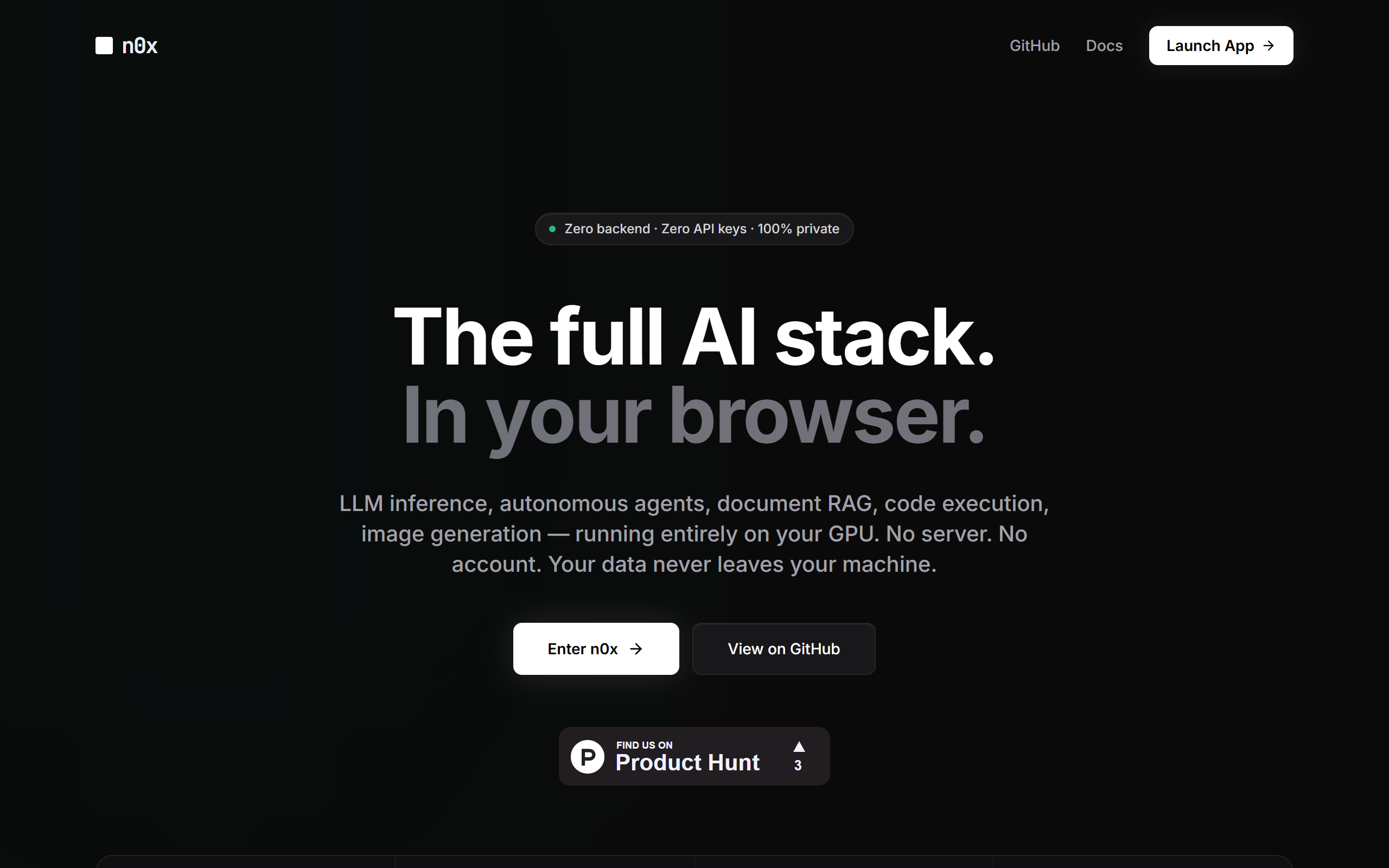
What is N0x?
Key features
LLM inference
Run large language models directly in the browser with WebGPU acceleration
Web search integration
Access real-time information from the internet within AI workflows
RAG (Retrieval-Augmented Generation)
Implement document-based AI systems for context-aware responses
In-browser Python execution
Write and run Python code without leaving the interface
Image generation
Create images using generative models entirely client-side
Memory and persistent context
Maintain conversation history and system state across sessions
Text-to-speech
Convert AI-generated or user text into natural-sounding audio
Pros & cons
Advantages
- Zero setup required, start using immediately without installation, registration, or account creation
- Complete privacy: all processing happens locally in your browser, no data sent to external servers
- No backend costs or infrastructure management needed
- Fast inference with WebGPU hardware acceleration for modern browsers
- Fully open access with freemium model removes barriers to experimentation
Limitations
- Performance depends on local device capabilities and browser WebGPU support, limiting execution on older hardware
- Browser memory and storage constraints may restrict model sizes and data processing capabilities
- Limited documentation or community support compared to established cloud-based AI platforms
Use cases
Rapid prototyping of AI agents and chatbots without backend infrastructure
Building RAG applications that reference local documents or web content
Educational exploration of LLMs and generative AI concepts
Privacy-sensitive applications where processing data locally is essential
Creating standalone AI-powered web applications that don't require server costs
Ready to try N0x?
Pricing
Free
Free
Full access to all features including LLM inference, code execution, image generation, web search, RAG, memory, and TTS with standard rate limits
Get started with N0x
Click through to N0x and start using it now.
- Free plan available
- No credit card