Natural Language Processing in Python by Steven Bird, Ewan Klein, and Edward Loper
Natural Language Processing in Python by Steven Bird, Ewan Klein, and Edward Loper - AI tool
- Freemium
- Web, Windows, macOS, API
- Data & AnalyticsAI Python Learning & DevelopmentAI Tools for Python
- Free plan available
- No credit card
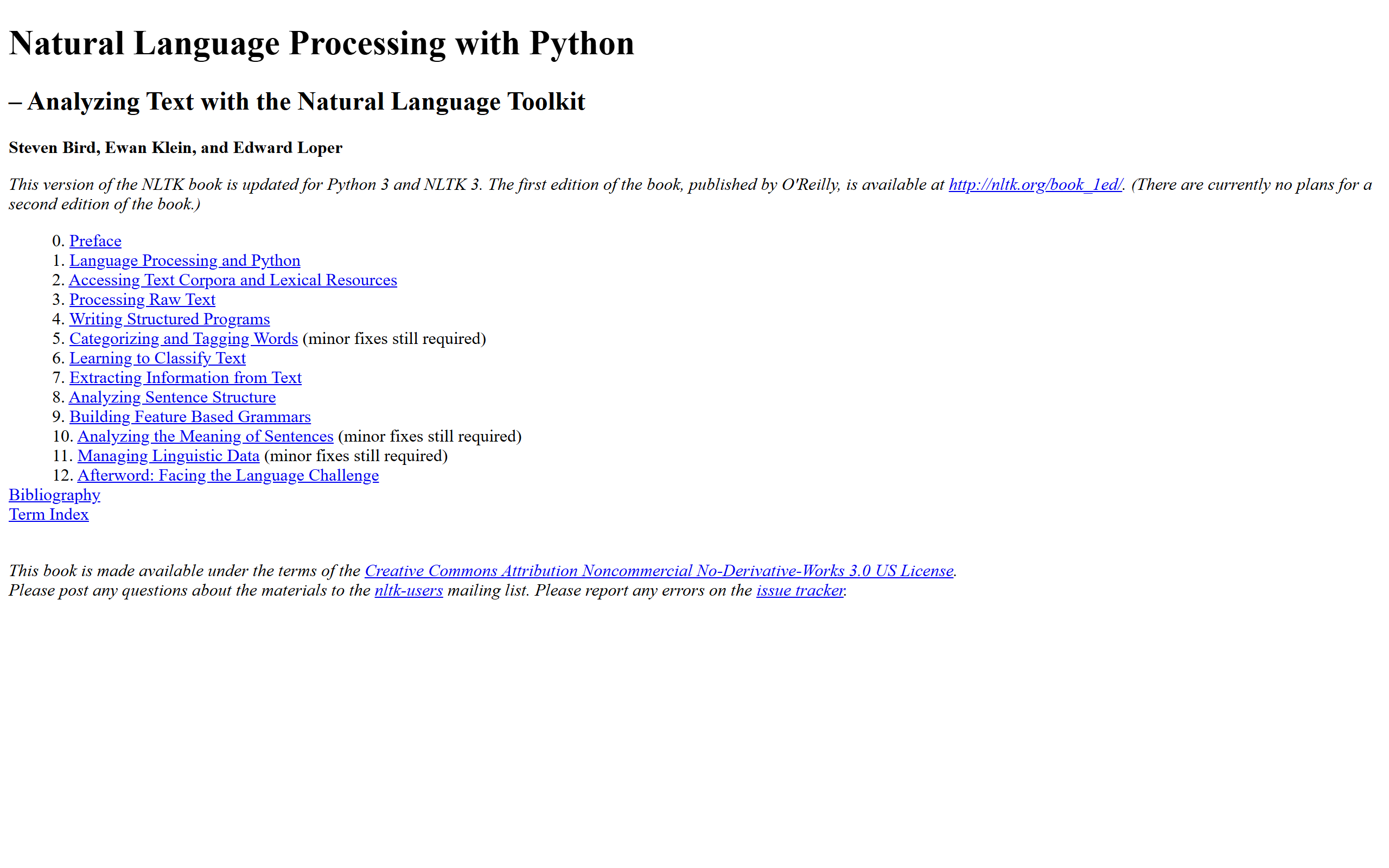
What is Natural Language Processing in Python by Steven Bird, Ewan Klein, and Edward Loper?
Key features
Online textbook
Free chapters covering NLP fundamentals, algorithms, and techniques with Python code examples
NLTK library
Pre-built functions for tokenisation, stemming, lemmatisation, and part-of-speech tagging
Sample datasets
Corpora and language datasets included for learning and experimentation
Interactive examples
Runnable code snippets throughout the book that demonstrate concepts in practice
thorough documentation
Detailed API documentation for all NLTK modules and functions
Community resources
Access to forums and community contributions building on the core toolkit
Pros & cons
Advantages
- Completely free, including the textbook and library
- Excellent for learning NLP concepts from the ground up with clear explanations
- Large collection of built-in corpora and linguistic data ready to use
- Active community with many third-party extensions and projects
Limitations
- NLTK is slower than some modern alternatives for large-scale processing tasks
- The textbook focuses on foundational concepts; advanced deep learning approaches receive less coverage
- Less actively maintained than some newer NLP libraries like spaCy or Hugging Face transformers
Use cases
Learning NLP fundamentals before moving to specialised tools
Building text classification and sentiment analysis projects for small to medium datasets
Academic research and coursework in computational linguistics
Rapid prototyping of language processing workflows
Extracting structured information from unstructured text
Ready to try Natural Language Processing in Python by Steven Bird, Ewan Klein, and Edward Loper?
Pricing
Get started with Natural Language Processing in Python by Steven Bird, Ewan Klein, and Edward Loper
Click through to Natural Language Processing in Python by Steven Bird, Ewan Klein, and Edward Loper and start using it now.
- Free plan available
- No credit card