
NMF
Uncover patterns, extract features, identify data relationships in large datasets.
- Freemium
- API, Web (Python environments), macOS, Windows, Linux
- Data & AnalyticsCode
- Free plan available
- No credit card
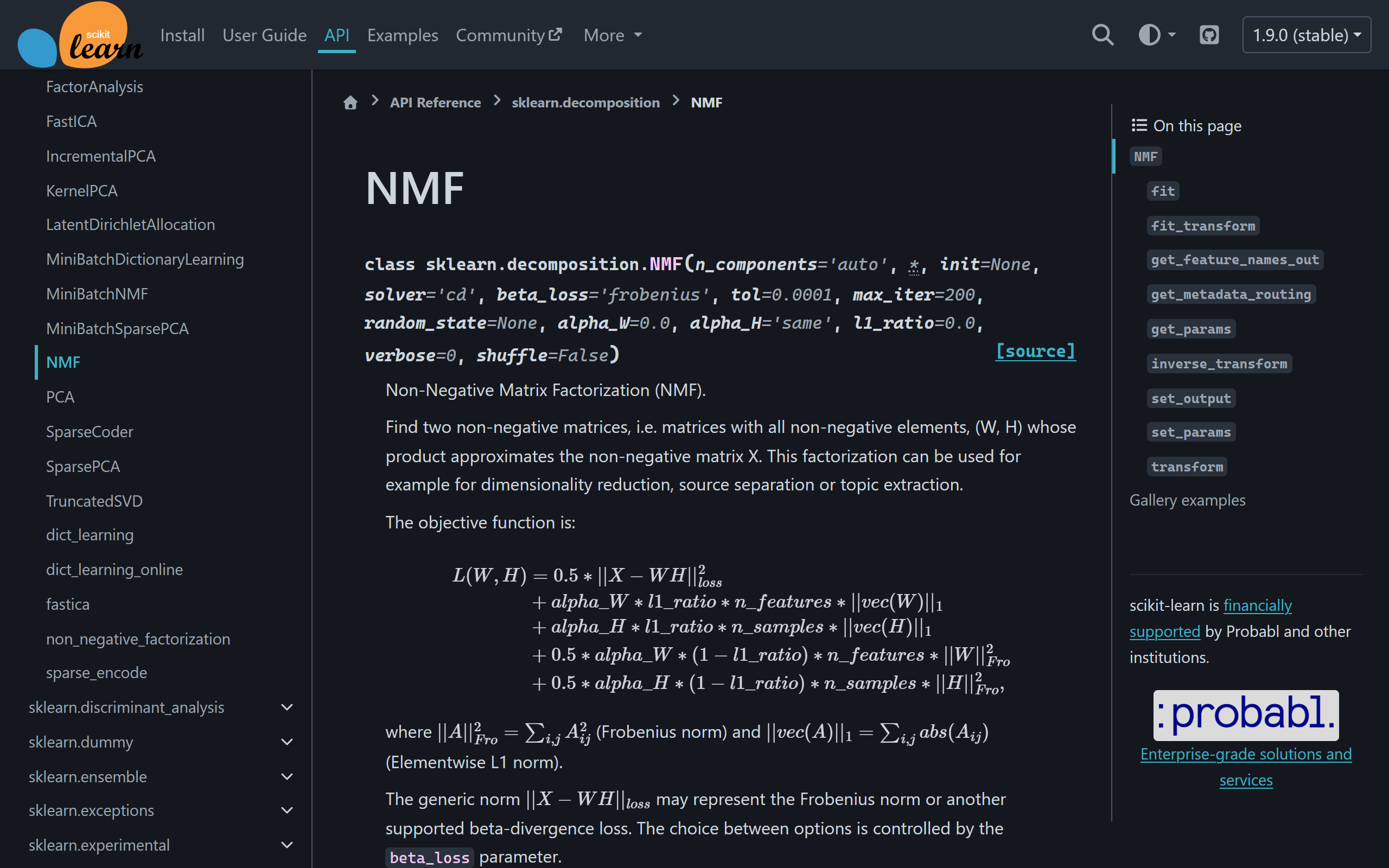
What is NMF?
Key features
Non-negative matrix factorisation
Decomposes data into non-negative factors, making results more interpretable than other methods
Multiple solver options
Choose between different algorithms (coordinate descent, multiplicative update, or HALS) depending on your dataset size and type
Integrated with scikit-learn
Works smoothly with the broader Python machine learning ecosystem
Sparse output support
Can produce sparse factor matrices for more efficient storage and computation
Customisable initialisation
Control how the algorithm starts to influence convergence speed and result quality
Built-in dimensionality control
Specify the number of components to extract from your data
Pros & cons
Advantages
- Free and open-source; no licensing costs or restrictions
- Results are interpretable because negative values aren't allowed, making patterns easier to explain
- Works efficiently with sparse data, which is common in real-world applications
- Well-documented with extensive examples in the scikit-learn community
Limitations
- Requires your data to be non-negative; preprocessing is needed if your dataset contains negative values
- Selecting the right number of components requires experimentation and domain knowledge
- Can be slower than some alternatives on very large datasets without careful parameter tuning
Use cases
Topic modelling: Extract main topics from document collections by analysing word frequency matrices
Image analysis: Decompose images into interpretable visual features or parts
Audio processing: Break down spectrograms into constituent sound components
Recommendation systems: Identify latent factors in user-item interaction matrices
Text mining: Discover underlying themes in text corpora for content analysis
Ready to try NMF?
Pricing
Get started with NMF
Click through to NMF and start using it now.
- Free plan available
- No credit card