
Opik
Evaluate, test, and ship LLM applications with a suite of observability tools to calibrate language model outputs across your dev and production lifecycle.
- Freemium
- Web, API
- SDKs & LibrariesIDEs & Editor ExtensionsDesign
- Free plan available
- No credit card
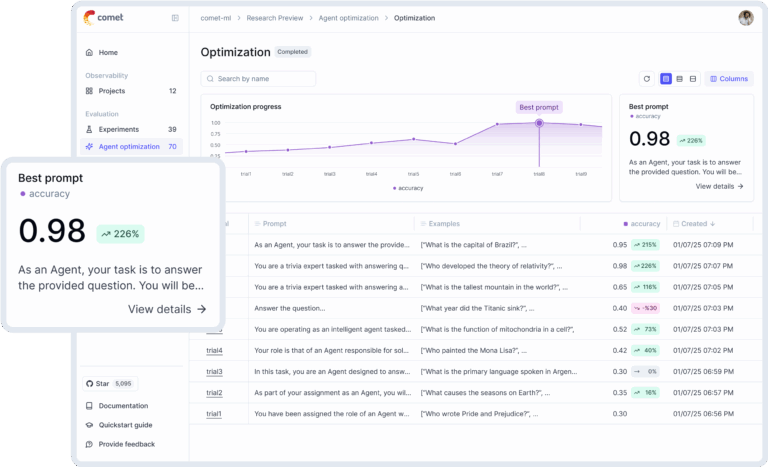
What is Opik?
Key features
LLM Evaluation Suite
thorough tools for testing language model outputs against custom criteria and benchmarks
Observability Across Lifecycle
Monitor and track model behaviour from development through production deployment
Output Calibration
Systematically evaluate and improve language model responses using metrics and scoring
Integration Support
Connect with popular LLM frameworks and development workflows via APIs
Comparative Analysis
A/B test different models, prompts, and configurations to identify best performance
Quality Metrics
Built-in and customizable evaluation metrics to assess accuracy, safety, and user satisfaction
Pros & cons
Advantages
- Addresses critical need for rigorous LLM testing before production deployment
- Freemium model allows teams to get started without immediate investment
- Provides continuous monitoring capabilities to catch performance degradation in production
- Supports data-driven decision making for model and prompt optimization
Limitations
- Learning curve required to set up thorough evaluation frameworks and metrics
- Effectiveness depends on quality of evaluation criteria and test data defined by users
- May require integration work with existing development pipelines and tools
Use cases
Pre-production evaluation: Systematically test LLM applications before shipping to ensure quality and safety
Prompt optimization: Compare different prompts and configurations to identify the best performing variants
Continuous monitoring: Track model performance in production and alert teams to quality degradation
Regulatory compliance: Maintain audit trails and evaluation records for compliance and governance
Model comparison: Evaluate different LLM providers or fine-tuned models to select the best option
Ready to try Opik?
Pricing
Pro
Custom pricing
Advanced evaluation features, priority support, higher usage limits, team collaboration
Enterprise
Custom pricing
Dedicated support, custom integrations, advanced security features, SLA guarantees
Get started with Opik
Click through to Opik and start using it now.
- Free plan available
- No credit card