
Replicate
Cloud platform for running, deploying, and scaling machine learning models with ease.
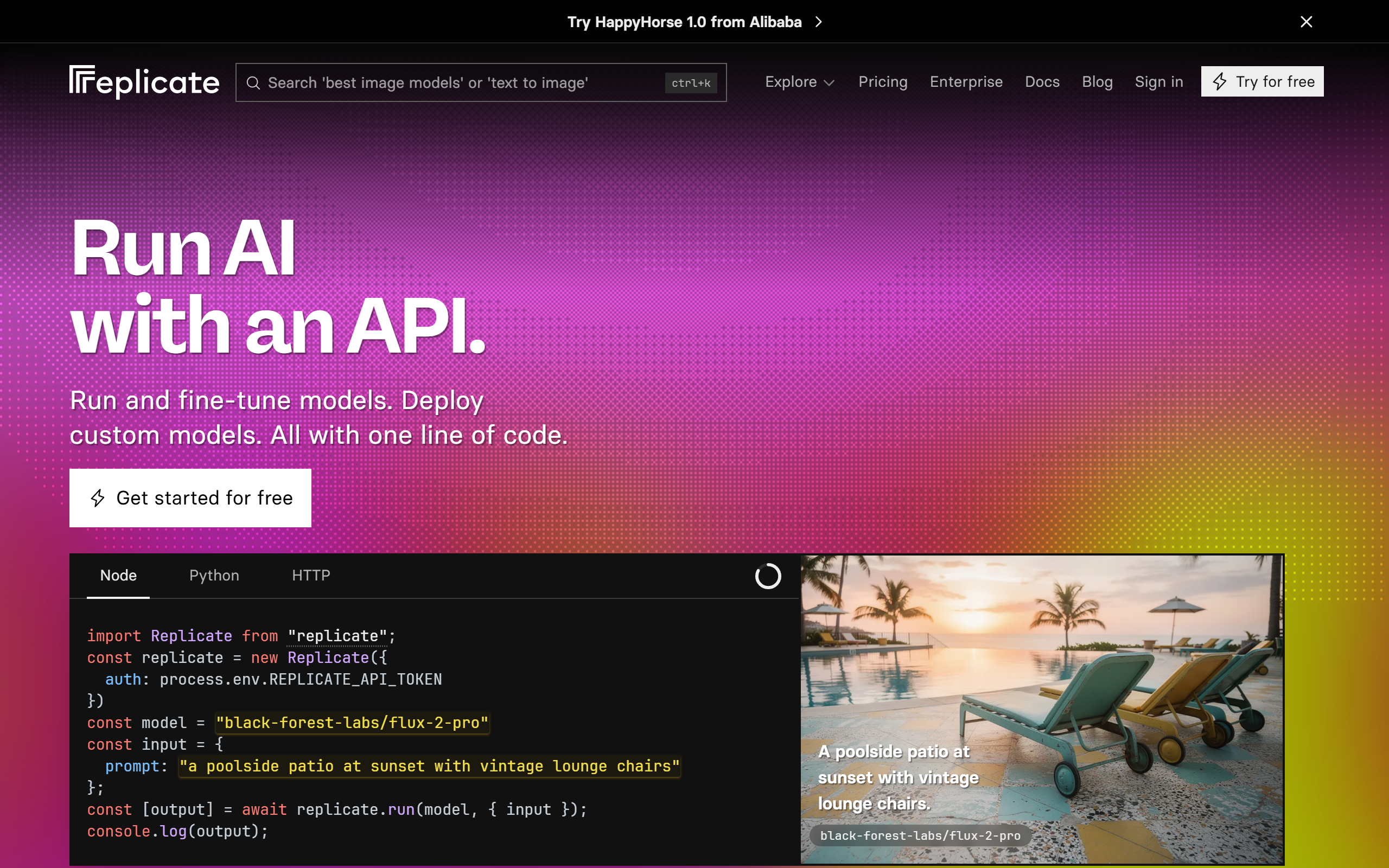
What is Replicate?
Key features
Model execution via API
Define your model once and access it through a HTTP API without writing server code
Automatic scaling
Infrastructure automatically adjusts to handle traffic spikes and quiet periods
Cog integration
Package models as containers using Cog, making them portable and reproducible
Pay-per-use pricing
You're charged only for actual compute time, not for idle capacity
Model marketplace
Browse and run thousands of open-source models from the community
Custom model deployment
Deploy your own trained models alongside public ones
Pros & cons
Advantages
- Quick to get started; minimal setup required to run your first model
- No infrastructure management needed; Replicate handles servers and scaling automatically
- Cost-efficient for variable workloads; you don't pay for unused capacity
- Works with popular open-source models out of the box
Limitations
- You're dependent on Replicate's infrastructure and pricing changes; less control than self-hosting
- Cold start latency may be noticeable for real-time applications during traffic spikes
- Limited transparency into exactly how much each request will cost before running it
Use cases
Building image generation features into web apps without hosting GPU infrastructure
Running inference on open-source language models for text processing tasks
Creating API endpoints for custom ML models trained in-house
Processing variable or unpredictable workloads where dedicated infrastructure would be wasteful
Prototyping ML features quickly before committing to permanent infrastructure
Ready to try Replicate?
Pricing
Pay as you go
Variable based on usage
Pay per second of GPU compute; scales with your needs; no monthly commitment
Get started with Replicate
Click through to Replicate and start using it now.